
Have you tried to explore Disaster Recover Solutions for SQL Server RDS. I am sure you might have had some frustrating moments, when the ask is upon you to give a DR solution for SQL Server RDS. Its weird, how well the cloud vendors promote their solutions faking the ability or our trusts are wrong. Every sentence in the realms of available documentation means a lot, and please read carefully.
We were tasked recently to come up with a DR plan for a production deployed SQL Server RDS. The architecture was currently running with DMS(Database Migration Service). If you are aware of it, it uses SQL Server’s own Transactional Replication and Change Data Capture features to cover for those tables with Primary Keys and those without respectively.
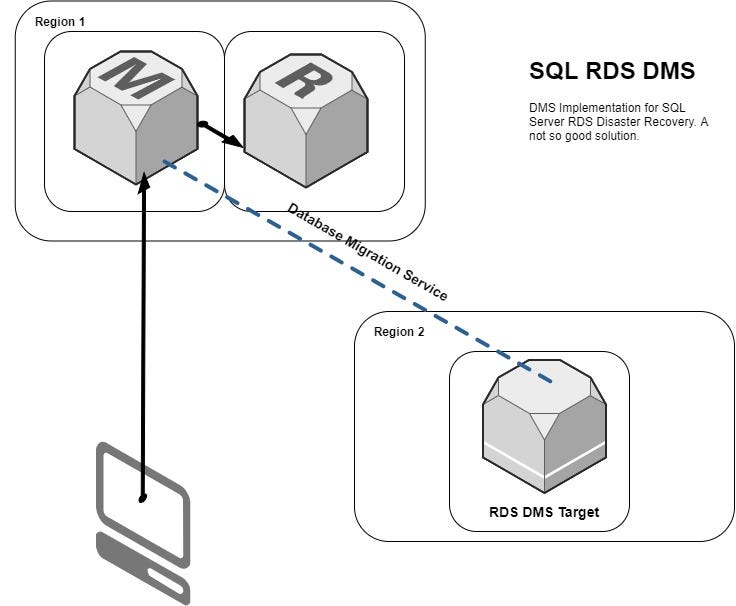
The DMS solution, though was working for us, had its own baggage. The BLOBs data was too heavy for the DMS. It took ages to replicate MBs of data. Hence was the push to come up with an alternate DR theory.
Our approach –
1. Take manual FULL backups and consequent Differential Backups every 30m and go on deleting the older ones for a day and restore it over DR. The problem with this method is, we will be wasting another instance in DR region to keep it running. And if you have worked on RDS SQL Server, as of today (29th Jun 2020), Log backups on the databases can’t be done on RDS(which we were told is being developed and should be available by year end 2020), so don’t waste time thinking about Log Shipping. Also, this method needs a S3 integration and cross region replication. You can opt to choose RTC while doing cross region replication, they promise 15m latency, but at an added price.
2. We thought about creating a read replica leveraging VPC Peering, it wasn’t possible either this way. Anyways, this was just a view that we wanted to explore, though we knew it wouldn’t work. We didn’t choose this way.
3. Snapshots — Everything on RDS leads to these snapshots. There are Automated and Manual ones. So, we chose this as a possible alternative. I will explain what we did — we reincarnated SQL Server Log Shipping to RDS Snapshots.
Below is a method you can leverage Systems manager service to ship the snapshots to any DR region for you to quickly make the data available. There are cons in this case too, but, we had comfort to maintain an RPO of 4hrs. Being a new exploration of the service, we were excited and wanted to share this here.
The plan was to automate manual RDS Snapshots using Systems Manager Document, copy them over to desired regions, and restore them.


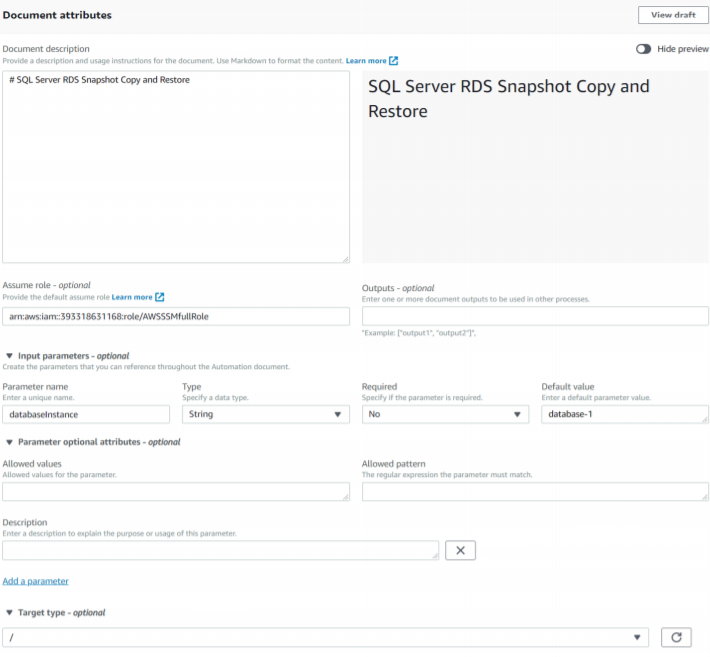
To achieve the above automation, systems manager service automation component is used by leveraging documents. An AWS Systems Manager document (SSM document) defines the actions that Systems Manager performs on your managed instances. More on this here. We had created automation document for our solution. Small extract from the AWS Documentation.


The finished document would look like below. You can add multiple steps and customize however you want the solution to operate.

The main section has options to give a Markdown Syntax description, define inputs/outputs(I have selected one input — database-1), add a role that can execute this document, select a target service where this document can be applied upon.

The main steps come below, in our document, we had 3 steps. The first one was to issue a RDS Snapshot on the input instance(database-1) that we had passed as a default to our document. The second one was to copy the snapshot to another region, and the restore step was optional. Third step was made optional since, we will not have a requirement to spin up multiple RDS Instances every time this automation works. Remember that the restore from Snapshot would create a new RDS Instance and endpoint will change. So, in our document, we had chosen to exit the automation after successful completion of the second step, i.e., copy snapshot step.

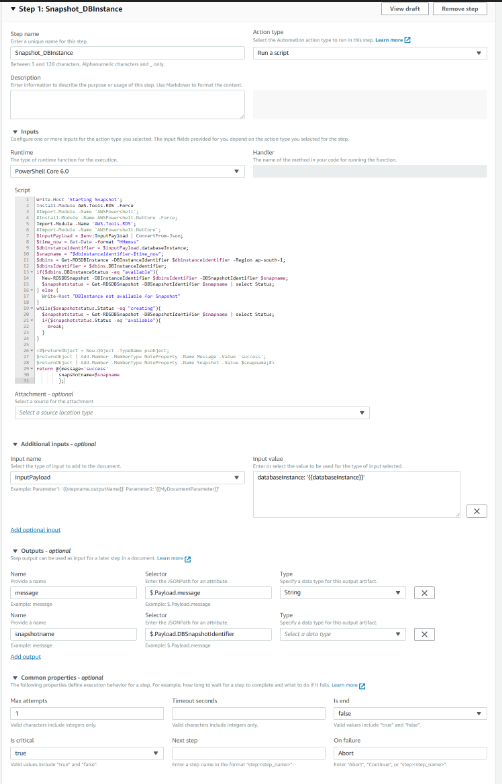
The adjacent picture shows the configuration of step 1, a name can be given and an action type should be specified. In our case this action type was to run a script. You can then go to Inputs section, wherein there are both python and powershell runtimes available. We chose Powershell run time. Remember this is Powershell Core 6.0. You should install the RDS module forcing it. You can choose to install any other service related module as per your preference.
Install-Module AWS.Tools.RDS -Force;
Import-Module -Name AWS.Tools.RDS;
You can add more input parameters. Using this feature, we could pass values between steps or declare some globally. For our solution, we wanted to pass the snapshot name from step 1 to step 2 and 3. We could use input output variables to achieve that. The last section in the step — common parameters — lets you choose the behavior of the step. You can choose to exit on its execution, retry times, etc.
Once we have the document created and tested, its time we schedule it. The systems manager has another component called State manager, that you can find under Instances and Nodes in the Systems Manager Page. We should just create an association in state manager for our document to run it on schedule. Below picture shows simple flow of state manager usage.


You can find the automation solution’s yaml file on my github here. If you have ideas to enhance this solution please let me know. Thanks for reading this blog post. Also, don’t hesitate to ask questions.
Comments
Post a Comment